Adaptive AI Agents & Foundation Model Integration
α-MaLe is Artificial Twin’s modular AI stack for building intelligent agents capable of perceiving, reasoning, and acting within dynamic, multi-modal environments. It integrates advanced techniques in Deep Reinforcement Learning, Foundation Model adaptation (LLMs, VLMs, VLAMs), and High-Fidelity Perception to enable fully autonomous and context-aware systems.
The stack supports simulation-first development, structured and unstructured data fusion, and scalable training pipelines that leverage GPU clusters and distributed compute. It enables agents to interact with language, visual scenes, and real-world constraints while evolving through feedback-driven adaptation.
Designed to meet the demands of critical industries, such as aerospace, defense, autonomous robotics, and synthetic training environments, α-MaLe powers systems that go beyond reactive behaviors: they learn policies, reason under uncertainty, and generalize across tasks and modalities.
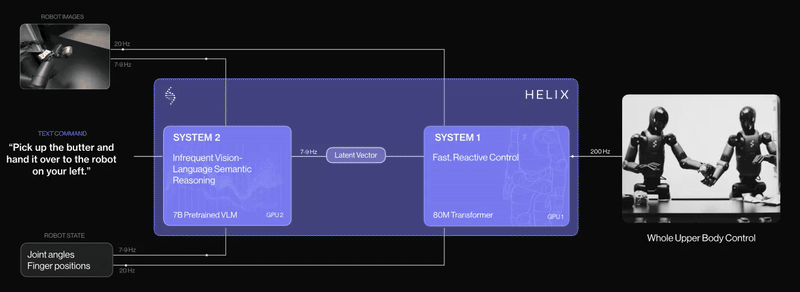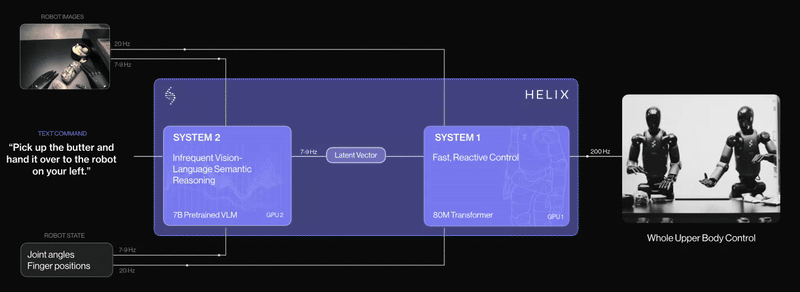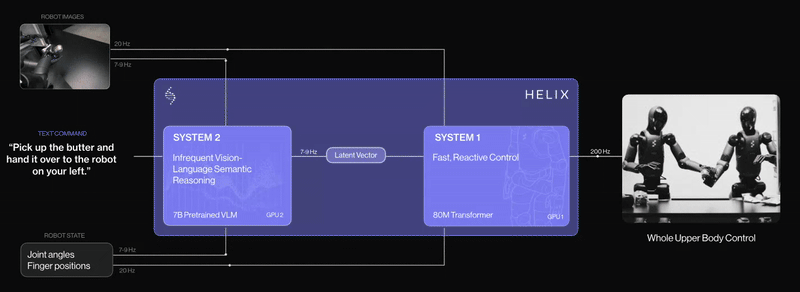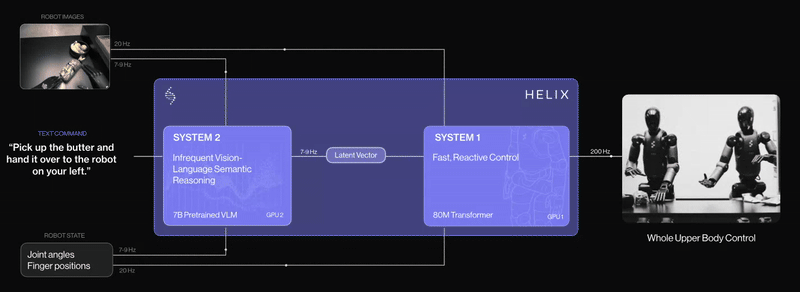

Reinforcement Learning at Scale
At the heart of α-MaLe lies a suite of tools to design and train adaptive agents via Reinforcement Learning. These agents can learn directly from simulation feedback or real-world signals to handle complex tasks such as swarm coordination, robotic control, or adaptive cyber defense.
We support:
- Online RL with curriculum learning, exploration boosting, and scalable distributed training
- Offline RL pipelines to learn from historical logs and simulation rollouts
- Imitation Learning and Behavior Cloning to bootstrap policies from expert behavior
- Adversarial and League Training for multi-agent competition or collaboration scenarios
- RLHF & RLAIF to align agents with human feedback and preference signals
From drones to space missions, α-MaLe delivers control systems that continuously adapt and evolve in complex, high-stakes environments.
Language and Vision Foundation Models
α-MaLe integrates workflows to train and customize Language, Vision, and Multimodal Foundation Models. Whether building a domain-specific assistant, improving scene understanding in simulation, or aligning agents with natural language instructions, we cover the full pipeline:
- SFT (Supervised Fine-Tuning): Aligning models with task-specific data
- RLHF / RLAIF / DPO: Reinforcing alignment with human preferences or synthetic feedback
- Multimodal & VLMs: Joint reasoning over vision-language inputs
α-MaLe supports high-performance training using CUDA, Triton, FSDP, and distributed strategies to accelerate experimentation and deployment of advanced LLMs, SLMs, and VLMs in client-specific contexts. It also includes capabilities for Visual-Language-Action Models (VLAMs), enabling agents to ground language in perception and action for more interactive, embodied intelligence across simulated and real-world environments.
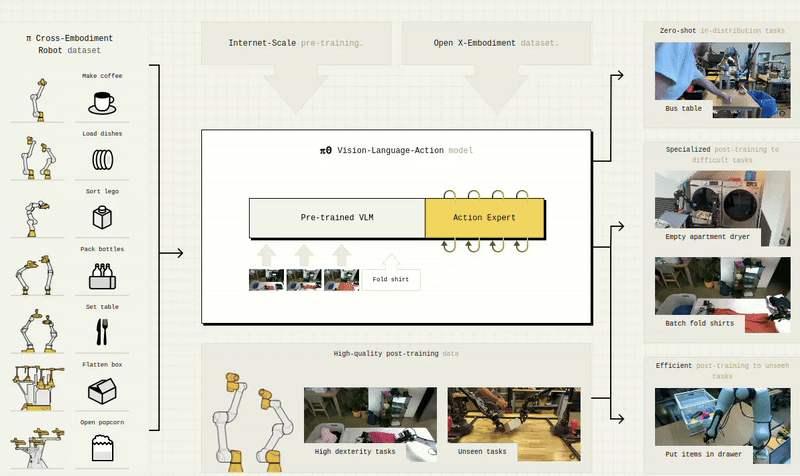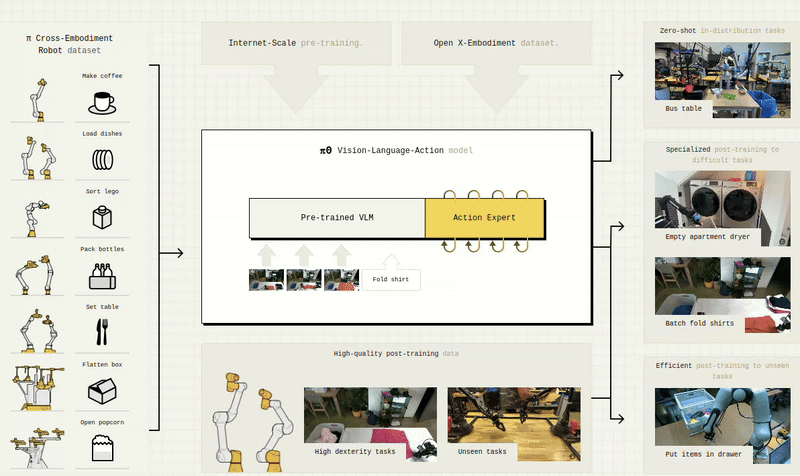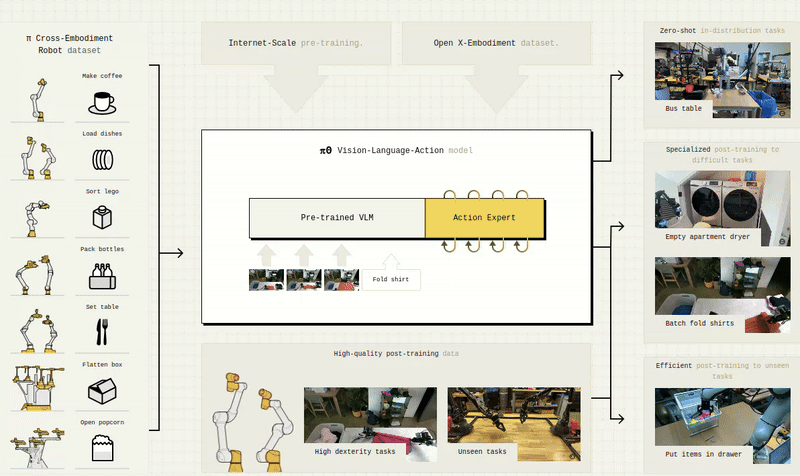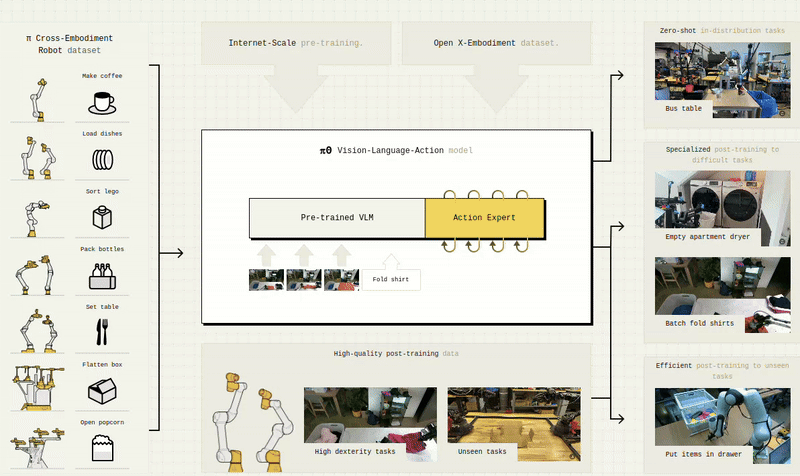
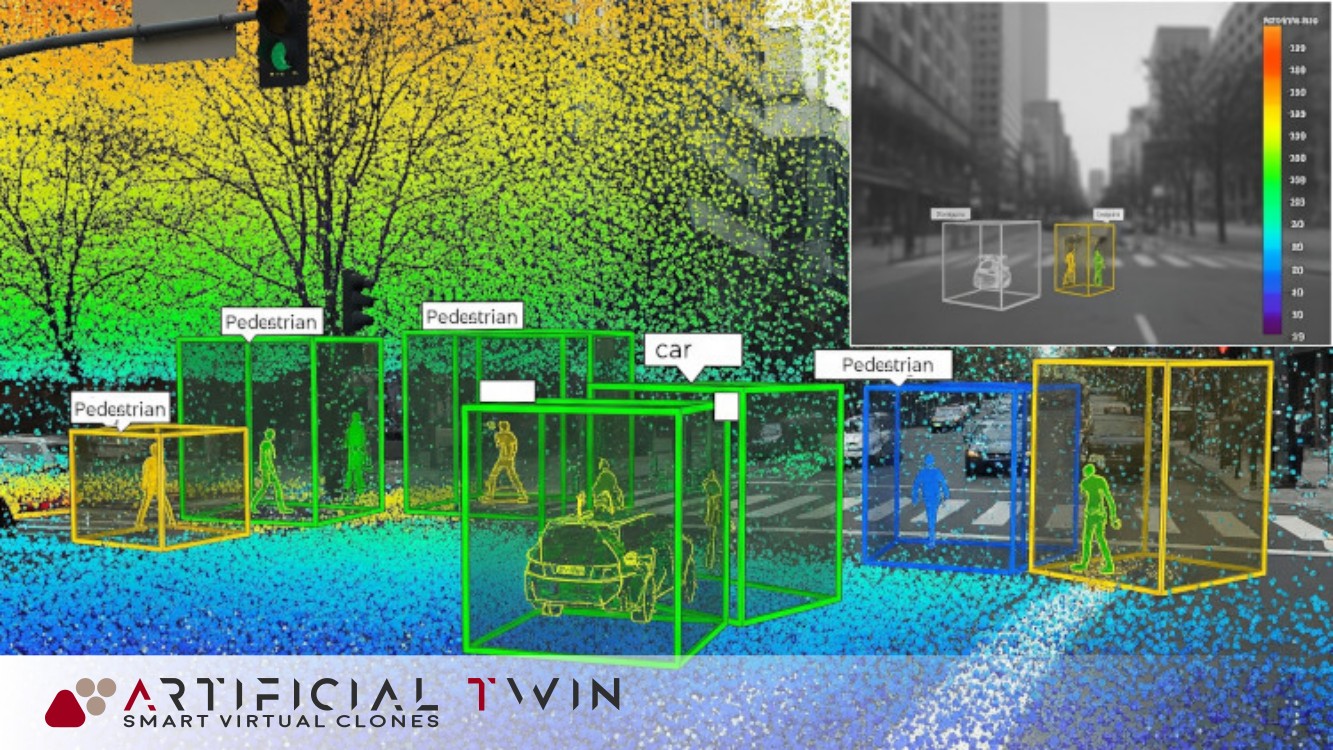
Visual Perception & Synthetic Understanding
Perception is critical for intelligent systems, and α-MaLe delivers computer vision modules that support tasks like:
- Object Detection & Tracking
- Semantic & Instance Segmentation
- Pose Estimation
- Depth Estimation & Multi-Camera 3D Reconstruction
- Multi-Modal Fusion (e.g., LiDAR + vision, radar + video)
Our perception stack is built for integration into simulated environments, real-time systems, or offline pipelines, enabling robust situational awareness and spatial understanding for agents operating in complex 3D spaces and dynamic, sensor-rich environments. These capabilities support navigation, targeting, and interaction in tasks where spatial precision and semantic comprehension are critical. From aerial robotics to synthetic training environments, α-MaLe bridges perception with intelligent action.
Simulation-First Learning and Control
Much of our work with α-MaLe is simulation-first: training agents in virtual environments before real-world deployment. This includes:
- Integration with simulators for robotics, orbital mechanics, UAVs, CFD, and more
- Looping simulation feedback into training for real-time performance improvements
- Domain randomization and curriculum strategies to improve generalization
- Bridging the sim-to-real gap with offline fine-tuning and hybrid learning pipelines
We enable our clients to prototype, test, and scale AI-driven systems with minimized real-world risk and accelerated iteration speed. α-MaLe also supports adversarial training, agent benchmarking, and scenario synthesis to explore edge cases before deployment.
Our modular interfaces allow for seamless integration of new environments and sensors, fostering rapid development cycles in high-stakes domains.
We also apply these capabilities to video game environments, where agents can be trained, aligned, and evaluated under diverse and challenging dynamics.


Deployment & Infrastructure
From fast experimentation to production-grade reliability, α-MaLe supports deployment across a range of infrastructures:
- Cloud-native platforms with distributed training and auto-scaling
- Edge or embedded deployments for real-time robotics and aerospace systems
- Desktop/local workflows for rapid prototyping and experimentation
- Integration with AI monitoring, observability, and evaluation pipelines
We provide tailored solutions that balance performance, cost, portability, and throughput, ensuring that models are not just trained, but shipped, tested, and continually improved. Our DevOps tools integrate with CI/CD pipelines and experiment tracking systems, enabling reproducibility and model governance. With support for containerized agents and remote deployment hooks, α-MaLe is production-ready from day one.