Problem Context
With the rapid rise of low-cost autonomous UAVs, defense systems must now contend with the possibility of large-scale kamikaze drone attacks that overwhelm conventional rule-based responses. The complexity of swarm behaviors, noisy detection data, and probabilistic engagement outcomes create a highly dynamic, high-stakes control problem.
Artificial Twin was brought in to design and train an RL-based decision support system capable of coordinating multiple kinetic effectors to protect strategically important zones from drone incursions. The system had to operate under uncertainty, with noisy observations and partial information, while making real-time targeting decisions.
This innovative solution enables defense operators to respond rapidly and intelligently to evolving swarm threats, significantly enhancing mission success rates.
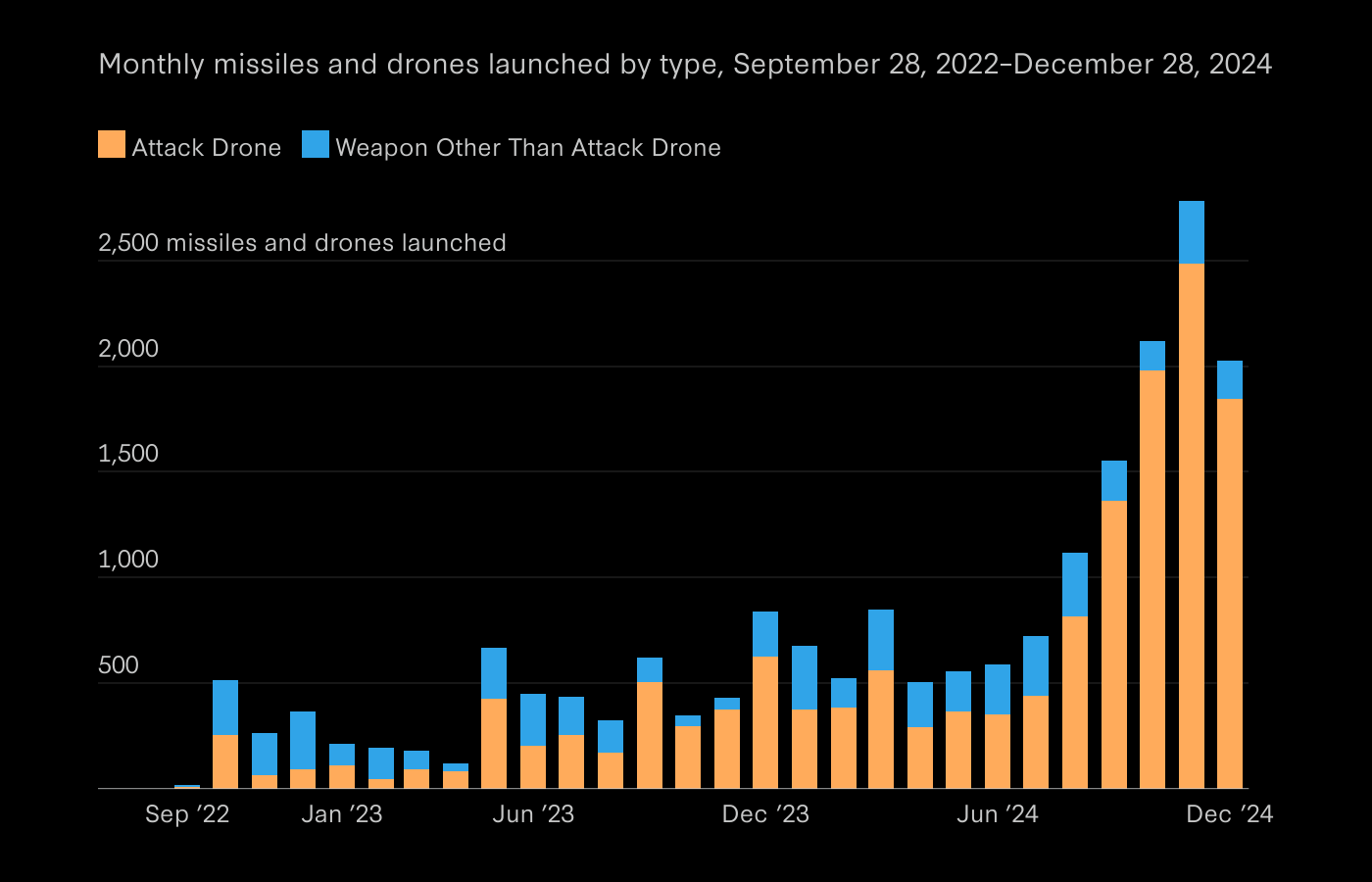
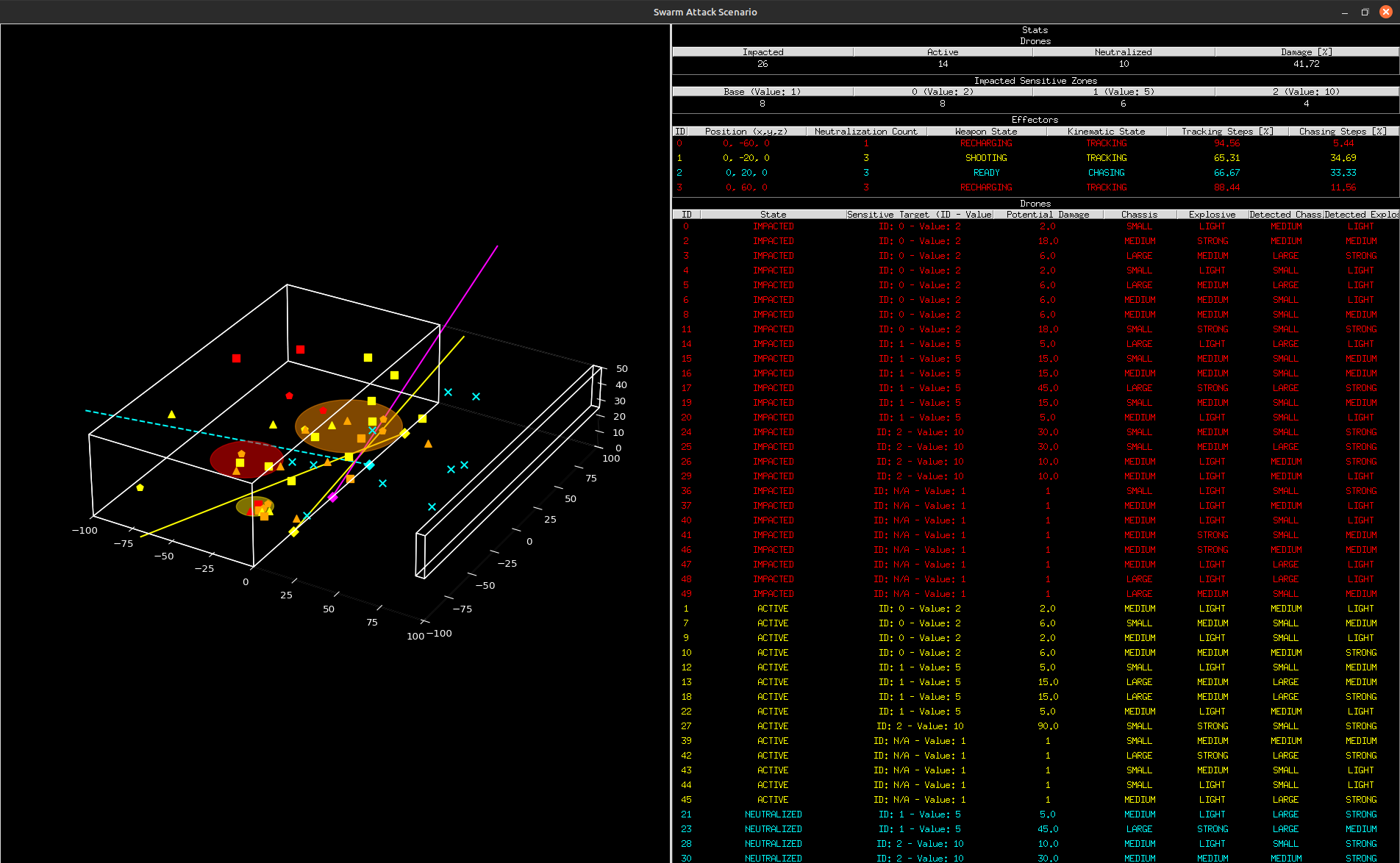
System Design & Simulation Architecture
To train and evaluate the RL policy, Artificial Twin developed a custom simulation framework that replicates the operational and stochastic dynamics of a swarm-based drone attack. The environment models kinetic effectors subject to targeting constraints and reload delays, alongside strategic zones that vary in criticality and incur weighted damage penalties. UAVs are simulated with randomized trajectories, sizes, and payloads, while noisy detections emulate real-world sensor uncertainty. Actions are selected discretely per effector, and the reward function is defined by the net damage sustained by the zones.
This comprehensive architecture enabled a diverse, research-grade training setup featuring scenario variability and probabilistic hit models, which proved ideal for shaping robust and adaptable policy behavior. By capturing the complexities and uncertainties inherent to real-world drone defense scenarios, the simulation ensured the RL agent developed effective and resilient decision-making capabilities.
The system supports rapid experimentation across hundreds of simulated missions, enabling large-scale policy comparison and fine-tuning. Built-in support for domain randomization also helps bridge the sim-to-real gap during downstream deployment.
Reinforcement Learning Approach
Artificial Twin employed a centralized Proximal Policy Optimization (PPO) framework to train a multi-effector control policy designed for dynamic, large-scale drone swarm defense. The agent operated on per-drone observation vectors containing noisy estimates of position, size, and payload type, and outputted discrete targeting actions for each effector in parallel, allowing for synchronized and scalable threat engagement.
The underlying neural network architecture was carefully engineered to support both policy expressiveness and training stability, and included:
- Structured input processing and observation normalization, ensuring the agent could learn consistently across a wide range of detection noise levels and heterogeneous input formats.
- Multi-layer perceptron-based policy and value heads, enabling the agent to reason over complex input data and optimize long-term performance through shared and task-specific representations.
- Reward normalization across episodes for training stability, mitigating variance from stochastic environments and sparse rewards, and accelerating convergence during multi-scenario training.
Key design goals included enabling multi-effector coordination, strategic allocation of threats based on real-time inference, and sample-efficient generalization across diverse and randomized swarm behaviors. Through interaction alone, without any hardcoded rules, the trained policy learned nuanced behaviors such as delaying fire to maximize cumulative effect, allocating drones to separate effectors to avoid redundant targeting, and prioritizing high-threat UAVs based on payload estimation and zone proximity.
[Input Obs]
|
[Flatten drones_zones_distance]
|
[Linear 150→64 + ReLU]
|-------------------------------|
| |
[pi_policy_net] [vf_value_net]
(Linear 64→64 + ReLU) (Linear 64→64 + ReLU)
| |
[action_net: Linear 64→200] [value_net: Linear 64→1]
Neural Network Architecture
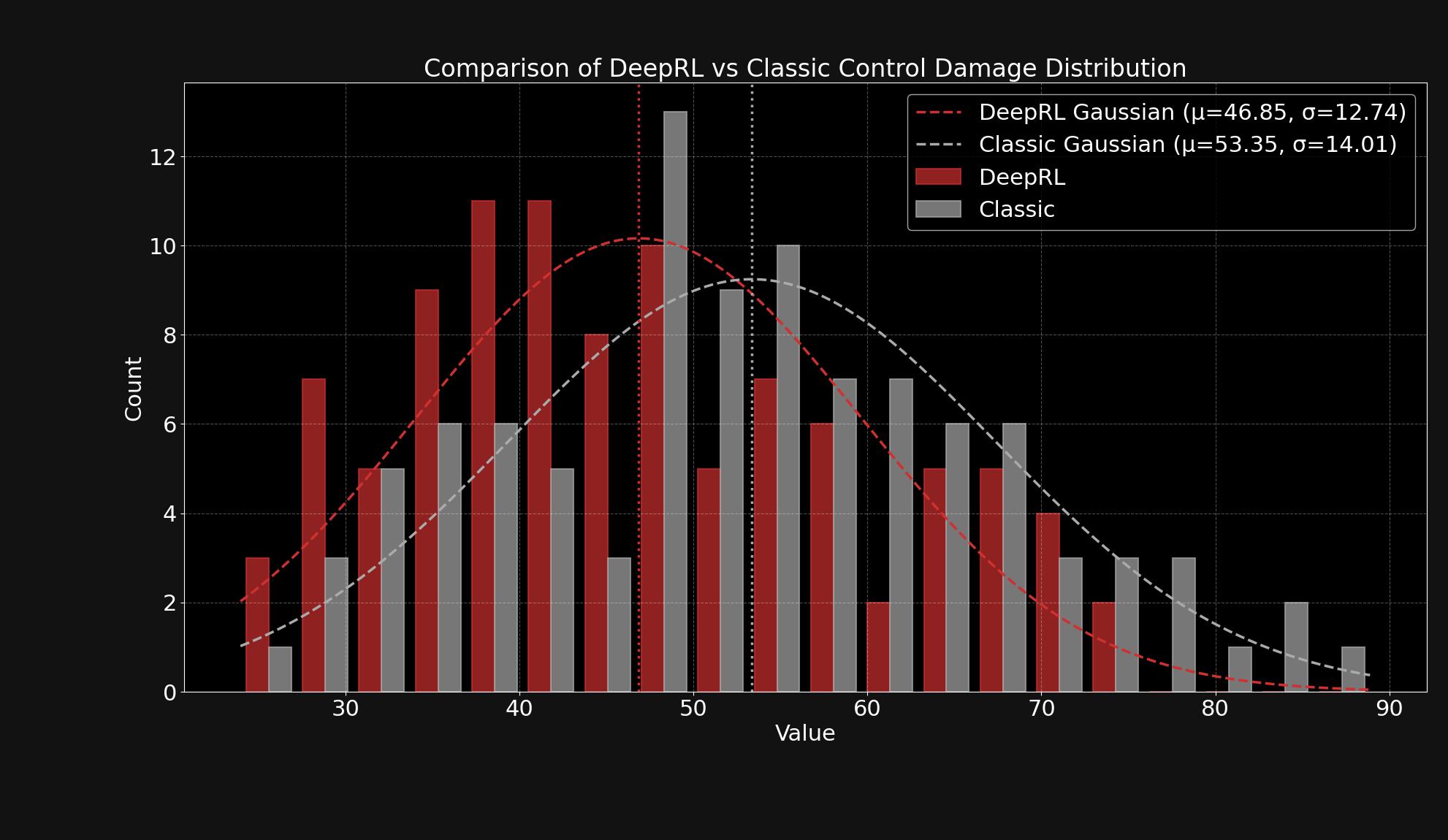
Evaluation & Comparison
To validate the approach, Artificial Twin benchmarked the RL agent against both a random policy and a handcrafted heuristic controller. The RL model consistently achieved lower average damage across hundreds of randomized attack episodes.
Evaluation metrics included:
- Total damage to sensitive zones
- Target tracking efficiency
- Weapon utilization
- Standard deviation in episode outcomes
- Behavioral comparisons under identical swarm conditions
The results showed the RL model developing nuanced prioritization strategies, outperforming baselines across performance and robustness metrics.
Reflections & Deployment Insights
Rather than acting as a direct actuator controller, the RL policy was positioned as a decision support layer, surfacing high-confidence threat prioritizations to human operators. This enabled:
- High interpretability and auditability of agent decisions
- Integration into human-in-the-loop workflows
- Adaptability to novel attack patterns without reprogramming
Artificial Twin’s solution illustrates how modern RL techniques can support mission-critical decision-making in safety-sensitive domains, bridging the gap between academic capabilities and operational viability.
Additional References
A techincal paper detailing the system design, training methodology, and evaluation results is available at the following link: Reinforcement Learning for Decision-Level Interception Prioritization in Drone Swarm Defense